[ THE OPERATING-MODEL GAP ]
AI marketing for banks looks fundamentally different at the institutions that are doing it well. Eight of the ten largest US banks are running regulated customer communications on a different production model than the rest of the industry. Not a different budget. Not a different vendor list. Not a different headcount structure.
A different operating model.
That distinction matters, because it means the gap is not structural in the way most institutions assume. It is not something that compounds with scale or requires a billion-dollar technology investment. The top-8 cohort reached this posture the same way any institution does: by deciding that "the way we've always built content" was costing them more than they could see on a single line item.
What follows is a diagnostic, not a pitch. Six operational shifts the top-8 cohort has already made. Each one is specific. Each one is reproducible. And each one is visible in the outcomes — speed, compliance performance, and campaign lift — that separate the top decile from the rest of the field.
If your institution is among the thousands that are not in the top-8 cohort, this is a peer-signal read. The posture shift happened. Here is what it looks like from the inside.
[ 01 — THEY'VE DECOUPLED THE BRIEF FROM THE TIMELINE ]
For most marketing and CRM teams at mid-tier and regional banks, the production calendar is the constraint. AI in banking marketing has not changed this for most institutions — brief submission still triggers a chain (copy, legal, compliance review, revision cycles, channel formatting, final approval) that runs anywhere from six to twelve weeks before a campaign is production-ready. That timeline is not a failure of process. It is the predictable output of a content architecture designed around human review at every handoff.
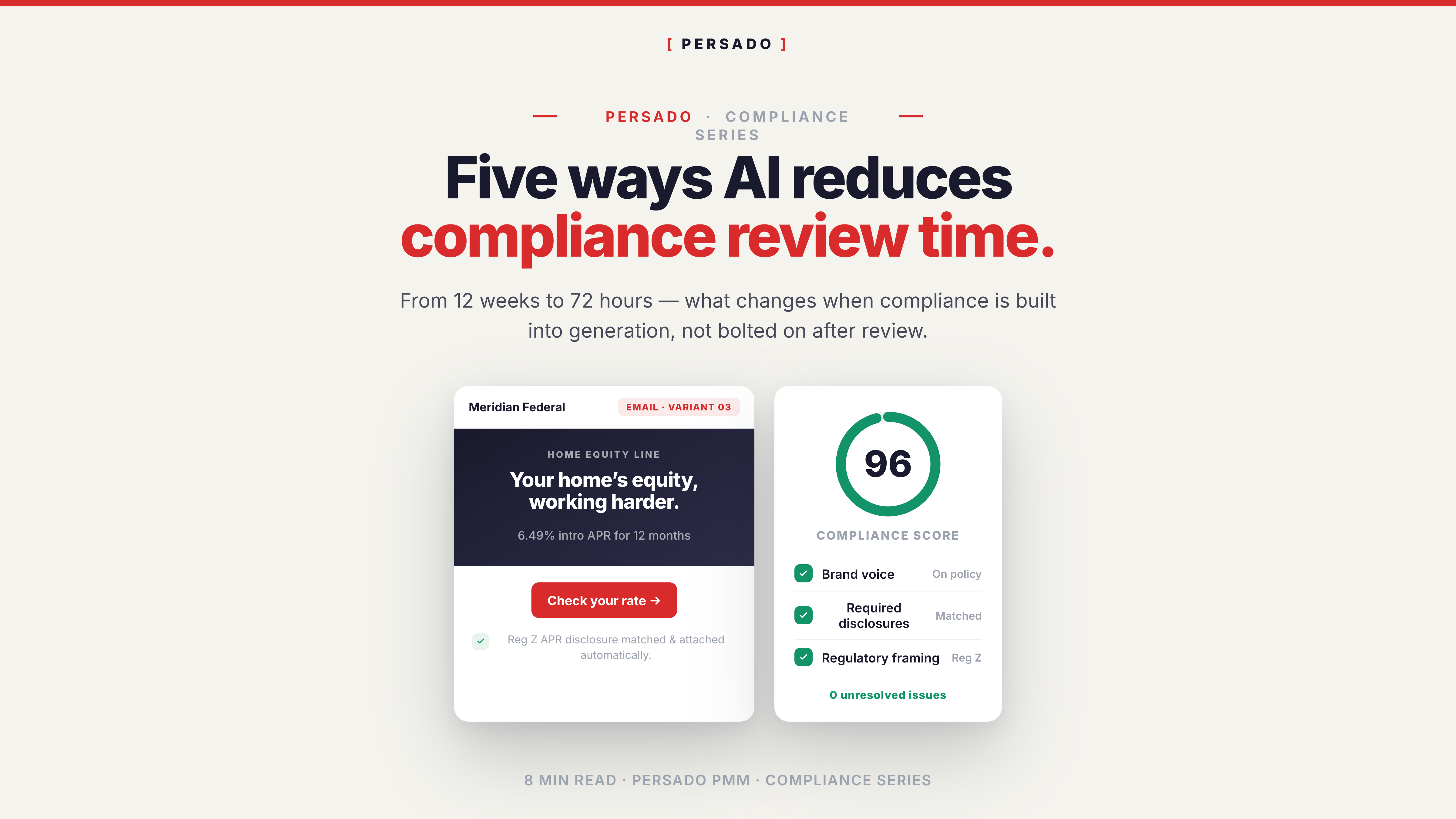
The top-8 cohort has changed the input-output relationship at the start of that chain. A brief goes in. Production-ready, performance-scored, channel-formatted, compliance-validated assets come out — in hours, not weeks. The verified benchmark: 12 weeks down to 72 hours, brief to production-ready.
The mechanism that makes this possible is not automation in the generic sense. It is a generation engine that holds your brand parameters, your channel templates, and your regulatory constraints as active inputs to the creation process, not as post-hoc review gates. There is no handoff to a separate compliance queue because the compliance logic is operating at the moment the content is written. There is no manual channel reformatting because the channel specifications are part of the generation parameters.
The result: your team stops managing a production queue and starts managing a performance portfolio. The brief is still yours. The thinking is still yours. The twelve-week drag between insight and execution is not.
This single operational shift — decoupling the creative brief from the production timeline — is where the compounding begins. Everything else in this list is downstream of it.
[ 02 — COMPLIANCE IS A SYSTEM PROPERTY, NOT A STEP ]
Ask a compliance officer at a mid-tier bank how regulated content gets approved, and the answer will almost always describe a sequence. Draft goes to legal. Legal marks it up. Marketing revises. Legal re-reviews. A specialist checks channel-specific disclosures. The cycle completes — or restarts. This is not a bad process. It is a rational response to an environment where non-compliance carries real institutional risk.
The problem is that this model treats compliance as a gate at the end of production. The top-8 cohort has moved it to the beginning — or more precisely, they have removed it as a discrete step entirely.
The mechanism: a Compliance Agent that operates at generation time, with 20+ regulatory frameworks — UDAP, FCRA, TILA, CAN-SPAM, TCPA, state-level consumer protection rules, and others — built into the parameter set that governs what can and cannot be generated. Content that would fail review cannot be generated in the first place, because the generation logic and the compliance logic are the same system.
The outcome is measurable: 90% fewer compliance rejections compared to generic AI drafts. The cause of that number is not better prompting or a more careful human reviewer. It is that the compliance constraints operate at generation time — what the [ PERSADO ] platform calls compliant at the point of creation — rather than at review time.
The institutional consequence is significant. When compliance is a system property rather than a workflow step, your legal team stops being a revision queue and starts being a governance function. That is a different use of expert time. It also means that moving faster on production does not mean accepting more compliance risk. Speed and compliance safety stop trading off against each other. The top-8 cohort has already made this trade-off disappear.
[ 03 — PERFORMANCE PREDICTION REPLACES POST-HOC REPORTING ]
The standard performance loop in most bank marketing organizations runs backward. You produce content, ship it, measure what happened, and apply lessons to the next cycle. The feedback lag is a campaign cycle. Sometimes longer. By the time the data tells you what worked, the moment it was relevant to has passed.
The top-8 cohort has inverted this loop. Every variant is scored before it ships. Not against a heuristic or a brand rubric — against 120K+ performance-labeled campaigns drawn from real regulated financial services contexts, with outcomes attached.
This is the "10s vs 12s" problem made operational. In a controlled test setting, the difference between an email that drives a 10% response rate and one that drives a 12% response rate is often invisible to human judgment before the send. The language choices that separate them are subtle — a single emotional register shift, a specific call-to-action construction, a claim framing that resolves anxiety rather than amplifying aspiration. Human copywriters and generic AI models cannot reliably detect this gap pre-send. The [ PERSADO ] performance scoring layer can, because the training corpus contains the outcome-attached signal that maps those choices to lift.
The mechanism: elements are decomposed via the Persado ontology, scored against outcome-weighted element-by-context combinations across the full campaign library, and ranked before the variant goes to channel. The score is not a confidence interval. It is a prediction grounded in 1M+ A/B tests mapped to real performance lift.
What this means operationally: your team stops optimizing after the fact and starts selecting from a ranked shortlist of predicted performers before the first send. Post-campaign reporting does not disappear — it feeds back into the corpus. But the decision that matters most, which variant to ship, is no longer made in the dark.
[ 04 — THE CORPUS IS THE MOAT — NOT THE MODEL, NOT THE PROMPT ]
This is the item that generative AI vendors would prefer you not to think too carefully about. Every organization with an API key and a well-crafted system prompt can run content through a large language model and get plausible output. Many do. The output is often grammatically correct, occasionally compelling, and structurally indistinguishable from agency copy — until you test it.
The top-8 cohort understood early that the model is not the differentiated asset. The training corpus is.
The [ PERSADO ] corpus: 1T+ messages analyzed. 1M+ A/B tests mapped to performance lift. 150B+ customer interactions. 100K+ message elements labeled by emotional register, intent signal, and channel context — all within regulated financial services. That corpus is outcome-weighted, meaning every element in it carries a signal about what actually moved a customer to act, in a regulated context, at scale.
You cannot prompt your way to this. You cannot fine-tune a general-purpose model on six months of your own campaign data and replicate it. The corpus is the accumulated behavioral signal of a decade of regulated financial services content performance, across the full customer lifecycle — acquisition, activation, engagement, retention, loss mitigation, cross-sell.
The 10/90 Rule applies here directly: 10% of performance differentiation comes from the model generating the language. 90% comes from the outcome-weighted training environment that tells the model what "performing" actually means in a regulated financial services context. Generic AI lives entirely in the 10%. The top-8 cohort is drawing on the 90%.
This is a structural advantage, not a transient one. The corpus grows with every campaign. The moat deepens with every send. The gap between institutions that are building on this corpus and those that are not is widening, not stabilizing.
[ 05 — THE SAME ENGINE HANDLES EVERY CHANNEL ]
Regional and mid-tier bank marketing teams often run implicit multi-agency models without naming them. Email is handled differently from push. SMS has a separate review path. Web copy goes through a different approval chain than app in-product messaging. Direct mail lives in a fourth lane. The friction is not always visible in an org chart — it shows up in timelines, in format inconsistency, and in the gap between what a campaign intends to say and what actually reaches the customer across every surface.
The top-8 cohort runs one engine across the full channel stack. Email. Web. Push. SMS. In-app. Each channel receives production-ready assets from the same generation layer, with channel-specific formatting and disclosure requirements built into the parameter set — not as a post-production adaptation, but as part of the initial generation.
The mechanism: brand parameters are set once and enforced at generation time across every channel template. The Brand Agent holds the voice, the approved terminology, the tone parameters, and the channel-specific structural rules. Output is channel-ready, not channel-agnostic-and-then-adapted. The compliance constraints that apply to SMS differ from those that apply to web — and the generation layer knows this, because the regulatory framework is mapped by channel in the compliance parameter set.
The operational consequence: your cross-channel campaigns say the same thing, in the right format, compliantly, on the first pass. You stop running a per-channel production operation and start running a cross-channel message strategy. That is a different use of your team's attention. It is also a different experience for your customer — consistency across every touchpoint, not consistency where the timeline allowed it.
[ 06 — OPTIMIZATION COMPOUNDS, NOT RESETS ]
The single-campaign A/B test is the standard operating unit of most bank marketing optimization programs. You run a test. You measure a winner. You apply the insight to the next campaign — usually manually, often incompletely, always with lag. The institutional knowledge of what worked and what did not lives in post-campaign reports that are read once and archived.
The top-8 cohort has replaced this model with one where every send teaches the next send, automatically, at the corpus level.
The mechanism: [ PERSADO ] maintains persistent learning across campaigns, not within them. When a variant outperforms in a specific customer segment, channel, and message context, that outcome signal is integrated into the scoring model for subsequent generation. The system learns your customers' behavioral signal over time — not as a static trained model that you retrain quarterly, but as a continuously updated performance layer that improves with every incremental data point.
The compounding effect is not theoretical. It is why a top-tier US card issuer running [ PERSADO ] over a sustained program period does not see the same performance distribution in year two that it saw in year one. The generation and scoring layers have accumulated more outcome-weighted signal specific to that institution's customer base, channel mix, and product context.
For a mid-tier or regional bank entering this model, the compounding starts from the corpus that already exists — 1T+ messages, 1M+ A/B tests, the full outcome-weighted library of regulated financial services performance data. You do not start from zero. You start from the accumulated learning of the industry's most performance-intensive marketing programs, and your own signal adds to it from the first campaign forward.
Single-campaign A/B testing does not disappear. It becomes the input to something that accumulates rather than resets.
[ THE SHIFT THE TOP-8 ALREADY MADE ]
The six shifts above are not independent tactics. They are a system. Brief-to-production speed is possible because compliance is embedded in generation. Performance prediction is reliable because the corpus is outcome-weighted at scale. Channel consistency is achievable because brand parameters and compliance constraints are unified in the same generation layer. Compounding optimization is real because learning persists across the full campaign library, not within individual tests.
This is what [ PERSADO ] calls the Agentic Creative Agency model: three agents — the Performance Agent, the Brand Agent, and the Compliance Agent — operating simultaneously at generation time, not sequentially in a review chain. The result is the positioning that the top-8 cohort has operationalized: Faster to Market. Built for Compliance. Proven to Perform.
None of those three outcomes is achievable at scale through legacy production workflows alone, and none of them is achievable through general-purpose AI without the corpus and the compliance infrastructure that makes generation safe in regulated environments. The top-8 cohort did not get here because they had more budget or better vendors. They got here because they changed the operating model — the architecture of how content moves from strategy to production to the customer.
The posture is reproducible. The corpus is already there. The framework registry covers the regulatory environment your institution operates in. And the 96% win rate against human-written and generic AI copy is not a benchmark from a controlled demo — it is the production record across the institutions that have already made this shift.
This post is a peer-signal read, not a close. If any of the six items above maps to a friction point your team is absorbing right now — a timeline that is too long, a compliance queue that is too slow, an optimization cycle that resets instead of compounds — the operating-model question is worth a conversation.
→ Talk to [ PERSADO ] about a Deep Market Scan on your portfolio. We will show you where the performance gap lives and what the production model looks like in practice. persado.com/contact
Related reading
• Generative AI in Financial Services Marketing — the canonical hub for AI in banking marketing across acquisition, lifecycle, and retention
• Persado for Financial Services — the industry solution view: card acquisition, mortgage, consumer banking, co-brand
• The 10/90 Rule of AI Content — the framework underneath items §03, §04, and §06 above
• AI Marketing Compliance — the pillar — the compliance-as-system-property thesis from §02
• The Marketing Content Supply Chain — the operating-model frame that sits above all six items